Improving the Speed and Accuracy of Bayesian Media Mix Models
 Marketing Measurement
Marketing MeasurementSeptember 23, 2025
By Benjamin Vincent
The data scientists at HelloFresh have a big job on their hands. As part of a rapidly growing company with a worldwide reach, they influence the allocation of marketing dollars every year. One of their tasks is to maximize new customer acquisitions from data-driven insights.
As part of their approach, the data scientists built a Bayesian Media Mix Model (see this video for more details). If you want a refresher of the power of Bayesian Media Mix Models, check out our previous blog post. But in short, MMM’s help us understand the characteristics and effectiveness of different marketing channels like TV, radio, podcasts, social media, daily deals, and more, based on how much we spent on each channel over time and how many new users we acquired.
Given the scale of HelloFresh’s operations, even minor improvements in the insights gained by such models can have significant effects on new customer acquisitions. Recently HelloFresh’s data scientists challenged us to do precisely this - could we (PyMC Labs) help them improve their already sophisticated Bayesian MMM?
What we delivered to HelloFresh
More accurate and precise model predictions
Thanks to PyMC3, we can build a model, feed in data, and press the Inference Button™. However, making high profile decisions requires due diligence! One crucial way of doing this is inspecting posterior predictive checks, which are plots comparing the model’s predicted customer acquisitions to the actual data. The closer the match between predictions and actuals, the greater confidence we can have in the model. By inspecting PPC plots, we could identify two key improvements to the model:
- We changed the outcome variable to be the logarithm of the number of new customers rather than the actual raw number. This can be useful in situations where there might be signal-dependent noise (i.e. more measurement error at higher customer levels) and allow the model to predict proportional changes in the number of customers.
- In addition, we reduced undesired effects on the parameter estimates by outlier data points by switching from a Normal likelihood function to a Student T distribution which is more robust to outliers.
With these two changes, we improved both the accuracy and precision of the model’s predictions. In the figure below the top panel shows the posterior of the original model and the bottom panel shows the posterior of the improved model. The comparison with actuals demonstrates reduced error and a 60% reduction in the variance of the predictions. The net result was that HelloFresh’s data science team could gain greater confidence that parameter estimates (such as channel efficiency or saturation) capture something meaningful about the world, providing greater confidence in making data-driven changes to marketing budgets.

In addition, we implemented the following enhancements:
- We changed the baseline static MMM by allowing parameters to evolve over time (we’ll expand upon this in the next blog post in this series).
- We changed how baseline customer levels and seasonal effects are added to the model.
- We performed a sensitivity analysis on the influence of COVID-19 on model stability.
10x speed up and additional insights
As the developers of PyMC3, we could leverage our considerable familiarity and expertise to deliver a 10x speedup to model inference time. By reducing a 20 min process down to just 2 mins, rapid iteration and experimentation become possible.
This was achieved through multiple methods, but particular attention was paid to the adstock function. Initially, this was implemented using an expensive convolution operation that scaled quadratically with the number of data points. We derived a linear-time algorithm for this specific case and implemented a custom theano operator with numba JIT compilation to achieve significant speedups.
Speeding up the model this much-allowed sensitivity analyses to be undertaken. We run hundreds of simulations under different priors to understand how it affected posterior estimates of the parameters. If parameter estimates are sensitive to priors’ variation, we know they are influenced less by the data and more by beliefs, which is not appropriate if priors are not supported by solid domain knowledge.
Improved interpretability of model parameters
We also reparameterized the reach function as:
Where
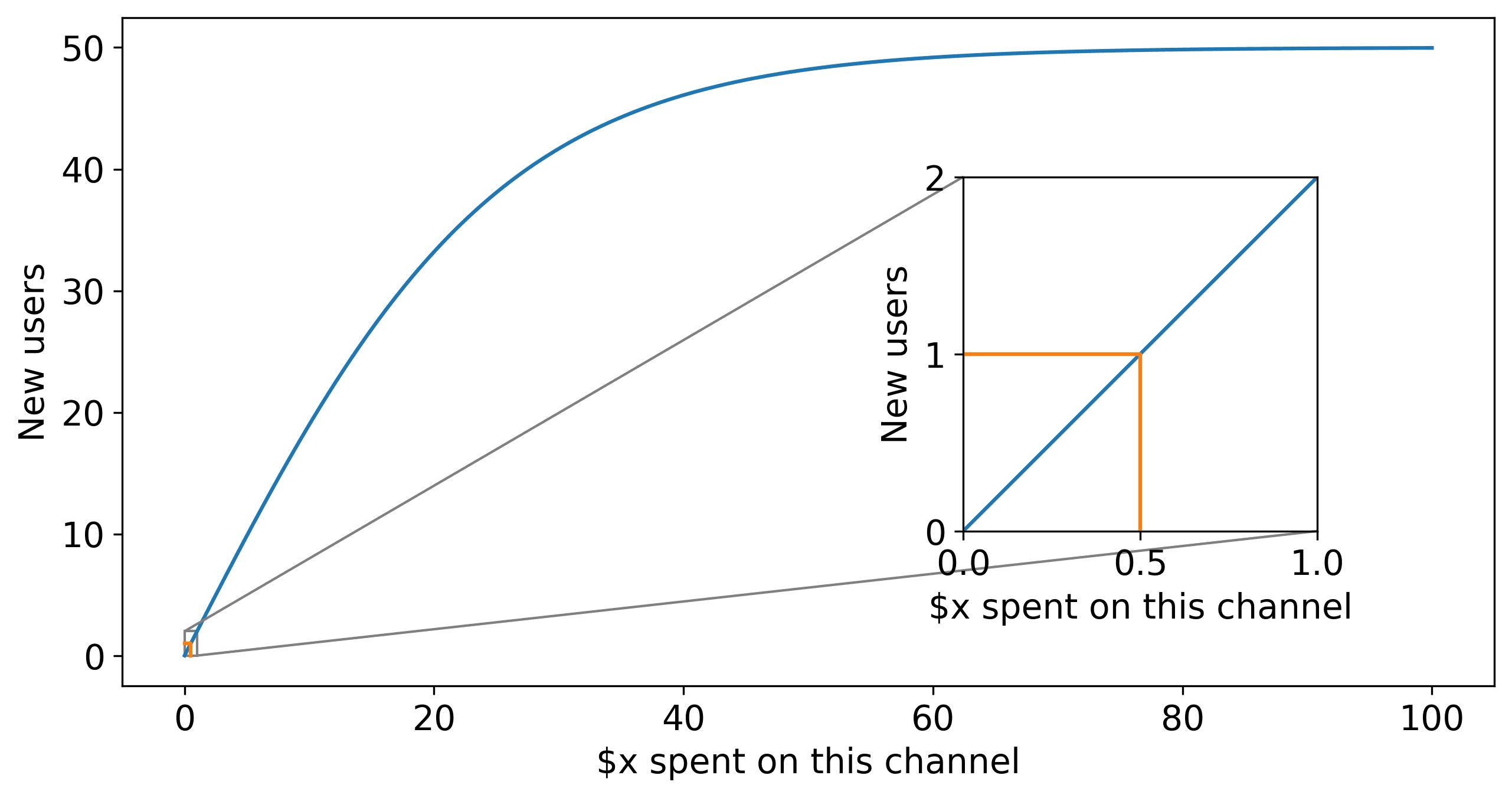
The full package
We work closely with clients to make sure we help solve their problems. But the code is just one part of that. We provided:
- Fully documented Jupyter notebooks that demonstrated the use of the new code.
- Weekly calls and project presentations to troubleshoot, keep goals aligned, and summarize our ongoing progress.
- Full training in the modeling and methods used so that the data science team was left empowered, able to experiment and debug independently from PyMC Labs long after the project was over.
- This, and other projects, have also benefited from pre-release functionality of PyMC3. For example, this project used a new
ZeroSumNormaldistribution which was not publically available at the time.
We and the HelloFresh data science team (check out their recruitment page) were delighted with the results of this project. But because Media Mix Modeling can be used in various ways, there are multiple routes for further progress. In fact, we are currently still working with the HelloFresh team on the topic. For example, Bayesian MMM’s can be used to optimally and automatically set budgets across media channels, rather than just informing those budgets. And those budgets can be used not only to maximize customer acquisitions but also to drive further learning and marketing experimentation where we have remaining uncertainty.