Use CasesBayesian Baseball Monkeys
Bayesian Baseball Monkeys
 Use Cases
Use CasesNovember 27, 2025
By Chris Fonnesbeck
The MARCEL baseball projection model, developed by Tom Tango, is a deliberately simple forecasting system for Major League Baseball (MLB) player performance. Named humorously after Marcel the Monkey, it aims to represent the "minimum level of competence" that should be expected from any forecaster.
Actually, it is the most basic forecasting system you can have, that uses as little intelligence as possible. So, that's the allusion to the monkey. It uses 3 years of MLB data, with the most recent data weighted heavier. It regresses towards the mean. And it has an age factor. -- Tom Tango
Yet, this minimalist approach makes it a transparent, reliable starting point for projecting player performance without requiring extensive computational resources or complex algorithms.
Key Features of the MARCEL Model
-
Data Utilization:
- The model uses three years of MLB data, with the most recent year weighted more heavily. This approach ensures that the projections are based on a player's recent performance while still considering their historical data.
-
Regression to the Mean:
- MARCEL incorporates a regression towards the mean, which helps to temper extreme performances and provide more balanced projections.
-
Age Factor:
- The model includes an age factor to account for the natural aging process of players, which can affect their performance. For most performance measures, this typically means improvement at younger ages, followed by decline at older ages.
Here is Tango's recipe for the model, taken from his website describing the 2004 version of the model:
- Weight each season as 5/4/3. 2003 counts as "5" and 2001 counts as "3".
- Determine each player's league average. I removed all pitchers' hitting totals from the league average. I lumped in AL and NL together. I weighted the player's league average using the 5/4/3 process and that's player's PA for that season. I then forced in that player's league average to come in at a total of 1200 PA for each player (2 weights x 600 PA). This is the regression towards the mean component.
- Add the above two.
- Determine the projected PA = 0.5 * 2004PA + 0.1 * 2003PA + 200. I take the result of #3, and prorate it to this projected PA.
- Determine an age adjustment. Age = 2004 - yearofbirth. If over 29, AgeAdj = (age - 29) * .003. If under 29, AgeAdj = (age - 29) * .006. Apply this age adjustment to the result of #4.
- Rebaseline the results against an assumed league average of 2003.
This description relates speficically to batter data, but the methodology can be applied to any annual player statistics.
A Bayesian MARCEL?
An interesting exercise is to consider how we might implement an analog of MARCEL using Bayesian methods. By incorporating a Bayesian framework, we can introduce uncertainty estimates into the projections, which can be valuable for risk assessment and decision-making. Moreover, a hierarchical model structure would provide a natural way to implement regression to the mean.
In the spirit of MARCEL, the goal here is not to have a sophisticated model for making accurate projections, but rather to have a simple, general purpose model that can be used to project arbitrary metrics, usually intended to provide baseline one-year-ahead projections. The only difference is that we will now have probabilistic uncertainty estimates around the resulting projections.
To this end, I've adapted the three core components as follows:
- Data weights for previous seasons estimated from the data using a Dirichlet distribution.
- A triangular aging function, whose midpoint is estimated from the data.
- A hierarchical random effect for league-wide mean regression.
Case study: Hard hit rate
As a motivating example, we will look at projecting batter hard hit rate. Hard hit rate (Hard%) measures the percentage of batted balls that are hit with exit velocities exceeding 95 miles per hour. Developed by Sports Info Solutions, it was originally based on a subjective classification of batted balls as either "soft," "medium," or "hard" hit. The introduction of Statcast data (via HitFX, Trackman, and now Hawkeye) allowed batted ball exit velocities to be measured directly.
Hard hit rate is often a leading indicator of performance in other statistics such as home run (HR) per fastball rate and batting average on balls in play (BABIP), while for pitchers, it can help explain their expected fielding-independent pitching (xFIP), among others. The league average hard hit rate is around 35%, so consistently exceeding this mark is generally considered positive for hitters (and concerning for pitchers). The relationship between hard hit rate and weighted on-base average (wOBA), a measure of batting performance that accounts for the quality of hit outcomes, is shown below, demonstrating an inflection around 95 MPH.
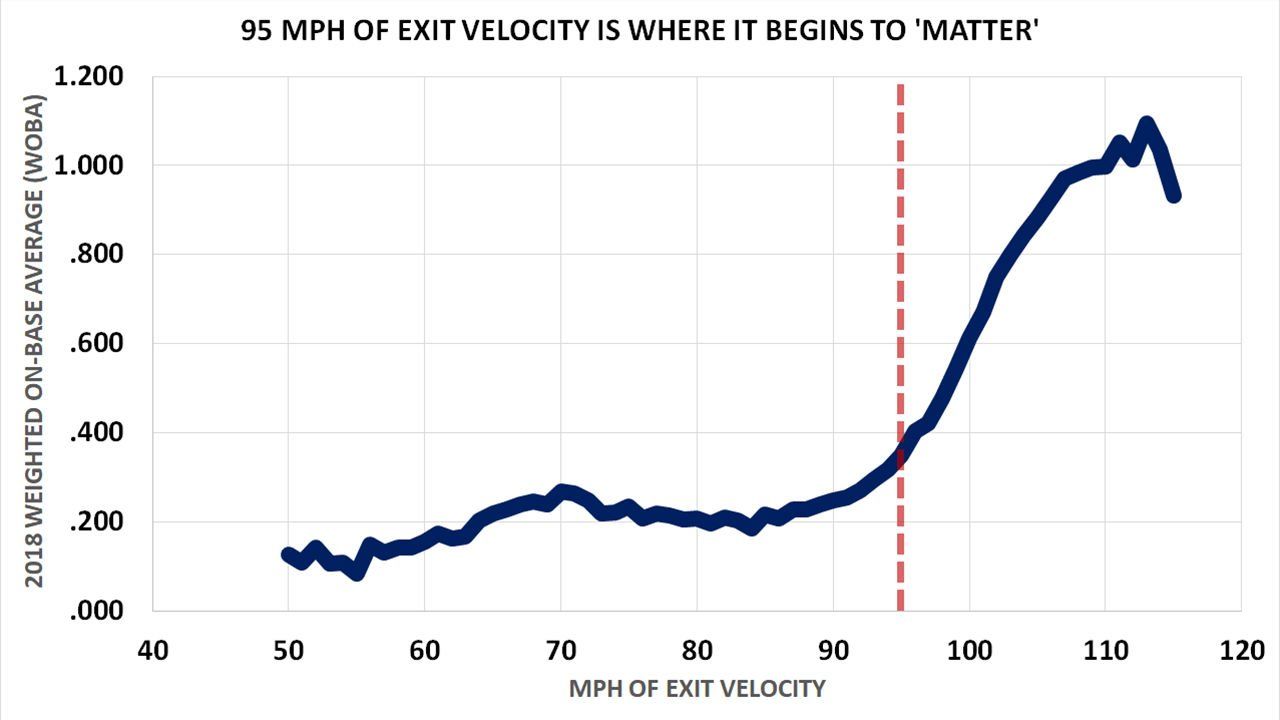 Image: mlb.com
Image: mlb.com
Data Preparation
It's generally pretty easy to get your hands on baseball data. We will use the pybaseball package to obtain the data that we need for this model. The package provides a convenient interface to the Statcast data, which contains detailed player statistics for each season.
Since MARCEL models require three seasons of data, we will use hard hit rates for years 2020 trhough 2022 to fit values observed in 2023, and then use the resulting parameter estimates to predict the 2024 rate from seasons 2021 through 2023. Therefore, we will query all batter data from 2020 through the games in 2024 at the time of this writing.
import pandas as pd
import numpy as np
import seaborn as sns
import pymc as pm
import arviz as az
from pybaseball import batting_stats
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
data = batting_stats(2020, 2024, qual=1)
hard_hit_subset = data[["Name", "Season", "Team", "Age", "HardHit", "Events"]].copy().reset_index(drop=True)
So, we will be using years 2020 to 2022 to fit to 2023 outcomes, where the target variable is observed hard hits (HardHit). The sample size will be the corresponding number of batted balls (Events) in each year.
For convenience, we are using players who have complete data over all 4 seasons. Incidentally, it would be easy to impute missing data to allow for the inclusion of players with partial data, but we are trying to keep things simple!
We need to do a little bit of data processing. Specifically, we need to pivot the data from long- to wide-format so that we have a row for each batter and columns representing each year of data.
hard_hit_by_season = (
hard_hit_subset.pivot_table(index=['Name'], values=["Events", "HardHit", "Age"], columns=['Season'])
.dropna(subset=[('HardHit', y) for y in range(2020, 2024)])
)
hard_hit_by_season[('Age', 2024)] = hard_hit_by_season[('Age', 2023)] + 1
Model formulation
Let's start by creating a PyMC Model and adding our data to it. Rather than just using NumPy arrays or pandas DataFrames, creating Data nodes in our model graph will permit us to easily generate predictions for new data after we fit the model.
fit_seasons = [2020, 2021, 2022]
coords = {
'batter': hard_hit_by_season.index.to_numpy(),
'season': fit_seasons,
}
with pm.Model(coords=coords) as marcel:
events_x = pm.Data("events_x", hard_hit_by_season["Events"][fit_seasons].to_numpy().astype(np.int32))
hard_hit_x = pm.Data("hard_hit_x", hard_hit_by_season["HardHit"][fit_seasons].to_numpy().astype(np.int32))
age_y = pm.Data("age_y", hard_hit_by_season["Age"][2023].to_numpy().astype(np.float32))
events_y = pm.Data("events_y", hard_hit_by_season["Events"][2023].to_numpy().astype(np.int32))
hard_hit_y = pm.Data("hard_hit_y", hard_hit_by_season["HardHit"][2023].to_numpy().astype(np.int32))
Let's start with the mean regression component of the model.
sns.histplot(data=data, x="HardHit%")
sns.despine(offset=10, trim=True);
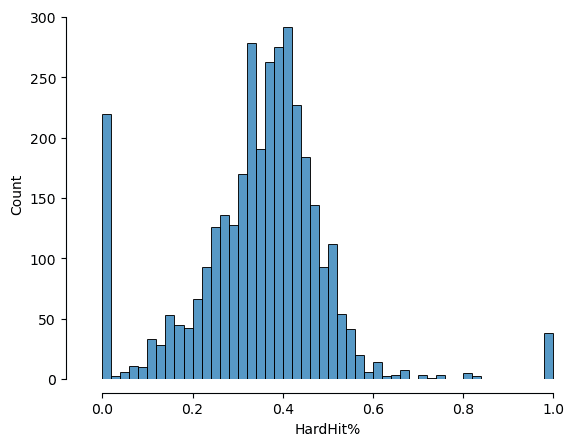 In the original MARCEL model, Tango dealt with this problem by calculating a weighted average of each player's observed data and the league average. Here, we will use a hierarchical model to partially pool the data according to the relative quantity of data for each player-season. Since we are modeling the number of hard hits per batted balls, a binomial sampling distribution with beta-distributed rates is appropriate.
In the original MARCEL model, Tango dealt with this problem by calculating a weighted average of each player's observed data and the league average. Here, we will use a hierarchical model to partially pool the data according to the relative quantity of data for each player-season. Since we are modeling the number of hard hits per batted balls, a binomial sampling distribution with beta-distributed rates is appropriate.
As we were told that the league average hard hit rate is around 35 percent, we can take advantage of the mean-variance parameterization of the beta distribution in PyMC:
Then, we can assign a weakly-informative priors to and :
with marcel:
# Empirical rates, regressed to mean with beta-binomial
mu_p = pm.Beta("mu_p", mu=0.35, sigma=0.2)
sigma_p = pm.Uniform("sigma_p", 0, 0.5)
p = pm.Beta("p", mu=mu_p, sigma=sigma_p, dims=("batter", "season"))
pm.Binomial("rate_like", n=events_x, p=p, observed=hard_hit_x)
The core of the Marcel projection model is the weighted averaging of previous seaons' observations. While the original model is a hard-coded a 5/4/3 weighting scheme, we will estimate optimal weights from the data, which is straightforward in a Bayesian framework. Thus, we are looking to project via:
where the are the latent partially-pooled rates from above.
The set of weights , in turn, are modeled with a Dirichlet distribution:
with marcel:
# Marcel weights
w = pm.Dirichlet(
"w",
a=np.array([3, 4, 5]),
dims='season'
)
# Raw projection
p_proj = p @ w
Finally, we implement the aging effect as a simple triangular (piecewise-linear) model on the logit scale, where the hard hit rate increases up to some "peak" age, and then decreases at the same rate thereafter. Both the value of the slope and the peak age are parameters of the model that we can estimate.
with marcel:
# Coefficient for triangular aging
beta = pm.Normal("beta")
# Estimate of peak age
peak_age = pm.Uniform("peak_age", data.Age.min(), data.Age.max())
age_effect = beta * (peak_age - age_y)
The projected rate is the age-adjusted weighted average of the latent rates over the three-year period, appropriately transformed to stay on the unit interval (see below).
with marcel:
projected_rate = pm.Deterministic(
"projected_rate",
pm.math.invlogit(pm.math.logit(p_proj) + age_effect),
dims="batter"
)
# # Likelihood of observed hard hits
pm.Binomial("prediction", n=events_y, p=projected_rate, observed=hard_hit_y, dims="batter")
Before we go ahead and fit the model, let's look at the model graph. It serves as a useful graphical summary of the model, and allows you to verify that you have specified the model correctly.
The shaded nodes are related to observed quantities in our problem, specifically the two likelihoods (ovals) and the data itself (rectangles). Open circles are the unboserved random variables, while the open rectangle is the expected hard hit rate, a deterministic sum of other model components. Enclosing plates denote vector-valued nodes, here confirming that we have included 332 players over 3 seasons in our analysis.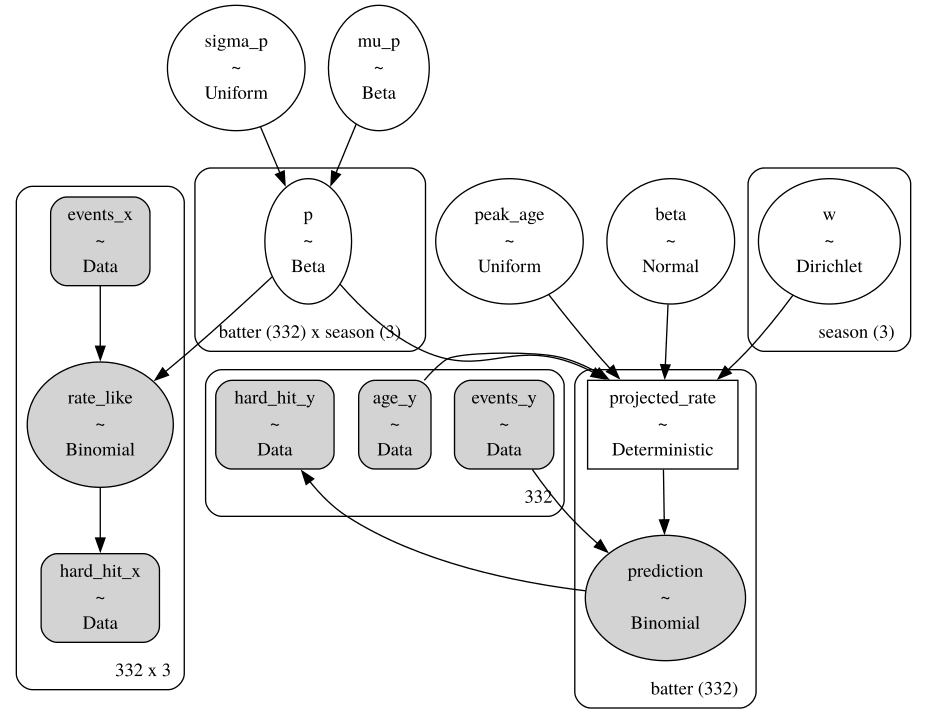
We will estimate the model using Markov chain Monte Carlo (MCMC) sampling, specifically the No-U-Turn Sampler (NUTS) algorithm, as implemented in PyMC v5. It should only take a few seconds to sample.
with marcel:
trace = pm.sample()
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 29 seconds. The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
You want to keep an eye on this output for any warning messages that may require additional intervention in order to improve the model. This example should run fine under the default arguments.
Model Checking
Even in the absence of warnings, its always important to check your model. In model checking, we want to know at least two things: did the model fitting algorithm work, and does the model fit the data adequately?
For the first part, we want to do convergence diagnostics because we have used a stochastic sampling approach (MCMC) to fit the model. That is, we want some assurance that the sampler converged to what the model specifies as the posterior distribution. This implies that the algorithm has had a chance to adequately explore the parameter space of the model.
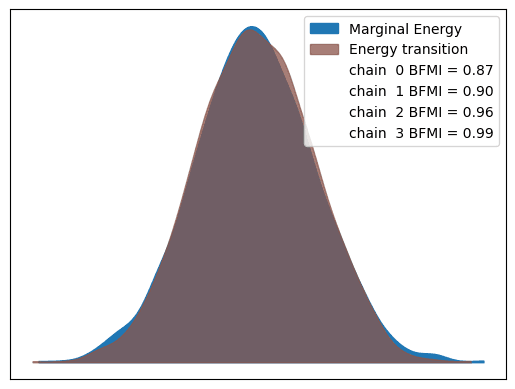
The az.plot_energy function will produce an energy plot of the fiitted model that gives a visual indication as to whether the model has been able to freely explore the parameter space. You will see two distributions: a marginal energy distribution and an energy transition distribution. It's not important to understand exactly what these are, but you are looking for these two distribtions to mostly overlap, as they do below. When they do not, the difference is usually rather dramatic.
az.plot_energy(trace);
 Another useful convergence diagnostic is the R-hat statistic, also known as the potential scale reduction factor. It compares the variance of chain means to the mean of chain variances across multiple chains, with values close to 1 indicating good convergence. If R-hat is substantially greater than 1, it suggests that the chains have not yet converged to a common distribution, indicating that more iterations may be needed.
Another useful convergence diagnostic is the R-hat statistic, also known as the potential scale reduction factor. It compares the variance of chain means to the mean of chain variances across multiple chains, with values close to 1 indicating good convergence. If R-hat is substantially greater than 1, it suggests that the chains have not yet converged to a common distribution, indicating that more iterations may be needed.
The sampler will return warnings if it detects large R-hat values for any of the parameters, but we can manually check them using the rhat function:
az.rhat(trace).max()
<xarray.Dataset> Size: 56B
Dimensions: ()
Data variables:
- beta float64 8B 1.001
- mu_p float64 8B 1.001
- p float64 8B 1.011
- peak_age float64 8B 1.002
- projected_rate float64 8B 1.007
- sigma_p float64 8B 1.0
- w float64 8B 1.005
xarray.Dataset
-
Dimensions:
- No dimensions available.
-
Coordinates:
- No coordinates available.
-
Data variables:
- beta: float64, 8B, 1.001
- mu_p: float64, 8B, 1.001
- p: float64, 8B, 1.011
- peak_age: float64, 8B, 1.002
- projected_rate: float64, 8B, 1.007
- sigma_p: float64, 8B, 1.0
- w: float64, 8B, 1.005
-
Indexes:
- No indexes available.
-
Attributes:
- No attributes available.
Despite the warning during sampling, these all look fine -- one value is borderline, but nothing to worry about.
If we are satisfied that the model has converged, we can move on to checking the model fit. This is largely the same idea as a model calibration check: seeing whether the model predictions correspond adequately to observed values. Since we have a Bayesian model, we can use posterior predictive checks for this. This involves generating simulated datasets from the fitted model, and comparing the simulations to the actual observed data (in this case, the data used to fit the model). If the model fits, we would expect the observed data to be indistinguishable from some random draw from the model.
pm.sample_posterior_predictive(trace, extend_inferencedata=True)
az.plot_ppc(trace, mean=False);
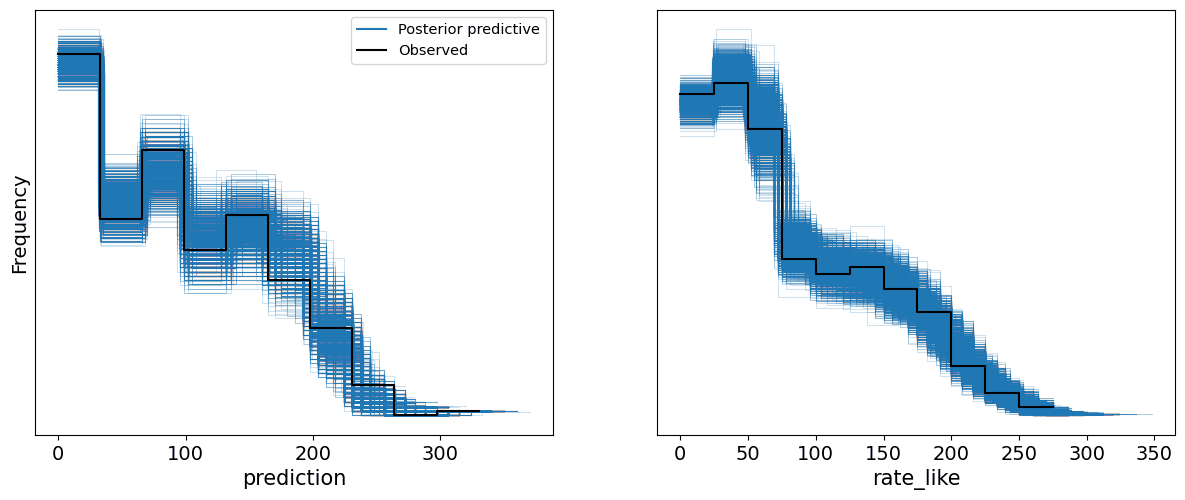
This doesn't look bad -- the observed data behaves like just another sample from the model.
Parameter Estimates
Having confirmed the fit of the model, we can move on to looking at some of the latent parameters and seeing if they make sense.
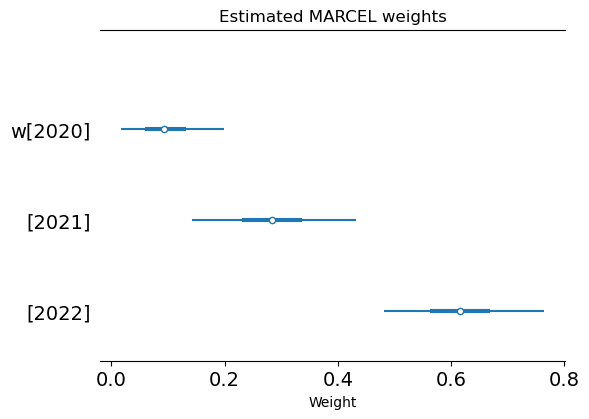
The estimated set of weights decline in magnitude with time, as we would expect. They correspond approximately to a 6/2/1 weighting, which gives the most recent season much more influence relative to the original MARCEL model and its 5/4/3 weighting. Recall that we used 5/4/3 as a prior weighting, but the evidence in the data shifted the weights away from this starting point.
az.plot_forest(trace, var_names='w', combined=True);
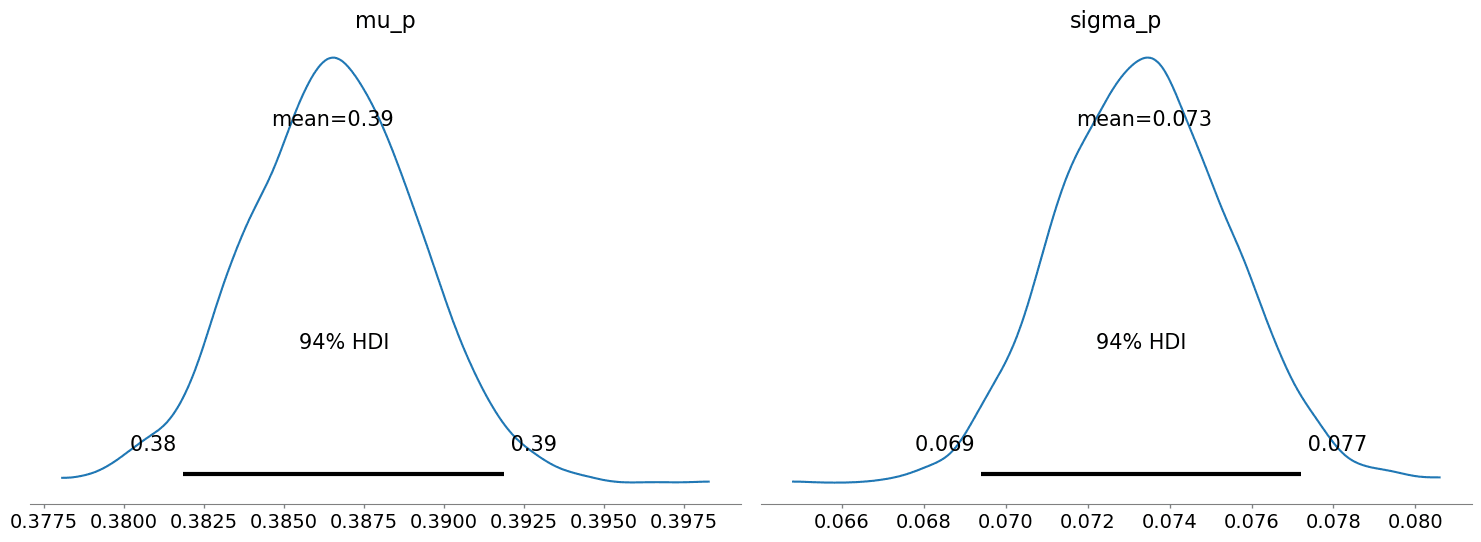
 From the posterior estimates below, we see that the mean hard hit rate is around 39%. Realistically, this value is probably best regarded as temporally dynamic, but we are resisting the urge to expand the model right now.
From the posterior estimates below, we see that the mean hard hit rate is around 39%. Realistically, this value is probably best regarded as temporally dynamic, but we are resisting the urge to expand the model right now.
az.plot_posterior(trace, var_names=['mu_p', 'sigma_p'])
plt.tight_layout();
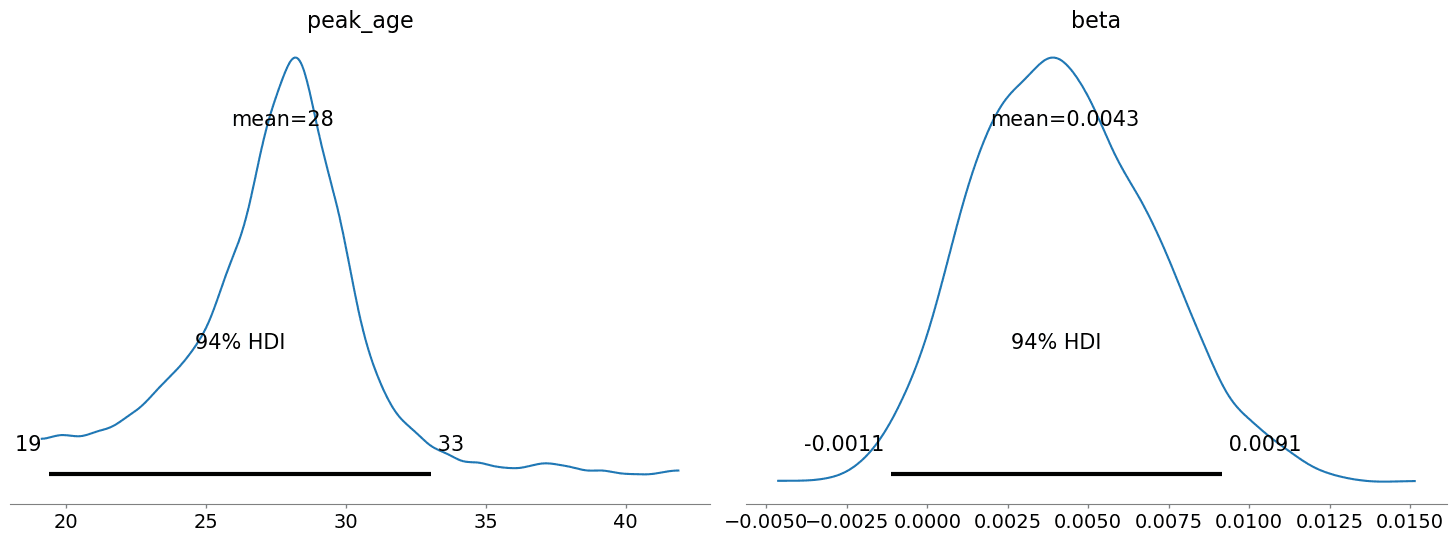
 What about the aging effect? The model estimates "peak" hard-hit age to be approximately 28 years (albeit with a wide range of posterior uncertainty), which seems a reasonable inflection point. The corresponding
What about the aging effect? The model estimates "peak" hard-hit age to be approximately 28 years (albeit with a wide range of posterior uncertainty), which seems a reasonable inflection point. The corresponding beta parameter is positive, indicating a positive slope at ages below 28 and negative above.
az.plot_posterior(trace, var_names=['peak_age', 'beta'])
plt.tight_layout();
Generating Projections
Once we have checked the model and are comfortable with the evaluation, we can use it to generate projections for 2024, using input data from 2021 through 2023. Here, we are not estimating anything; we are merely applying the fitted model parameters to a new set of inputs.
In PyMC, the set_data function is used to replace existing data in the model with new data, after which we can use the sample_posterior_predictive function to generate predictions. This performs forward sampling, drawing values from the posterior distributions we have estimated and using them to simulate projections. For this model, predictive sampling should be almost instantaneous.
pred_seasons = [2021, 2022, 2023]
with marcel:
pm.set_data(
{'age_y': hard_hit_by_season["Age"][2024].to_numpy().astype(np.float32),
'hard_hit_x': hard_hit_by_season["HardHit"][pred_seasons].to_numpy().astype(np.int32),
'events_x': hard_hit_by_season["Events"][pred_seasons].to_numpy().astype(np.int32)
}
)
pm.sample_posterior_predictive(trace, var_names=['projected_rate'], predictions=True, extend_inferencedata=True)
Let's take a peek and see how the model performs. Below are predictive intervals for each player's expected hard hit rate in 2024, along with the observed rate (which, keep in mind, is only for about a half-season). To help evaluate the predictions, the observed rate is color-coded by sample size -- darker red indicates a larger sample size.
The model performs well, considering how stripped-down it is. The weighted averaging and partial pooling components have done a nice job of protecting the model from overfitting. The sharing of information via the hierarchical component also means that the predictive intervals are narrow, even for players with relatively sparse data.
If we focus on the players with substantive sample size (i.e. those with dark red data points), we can potentially identify hitters that are over- or under-performing. Certainly, Juan Soto, Ketel Marte, and Marcell Ozuna are having great seaons so far, while Whitt Merrifield was released by the Phillies shortly before this writing.
p_obs = (hard_hit_by_season['HardHit'] / hard_hit_by_season['Events'])[2024].fillna(0)
axes = az.plot_forest(trace.predictions['projected_rate'], combined=True, figsize=(6, 72))
axes[0].scatter(p_obs.values[::-1], axes[0].get_yticks(), c=list(hard_hit_by_season.Events[2024].fillna(0).values[::-1]), cmap='Reds');
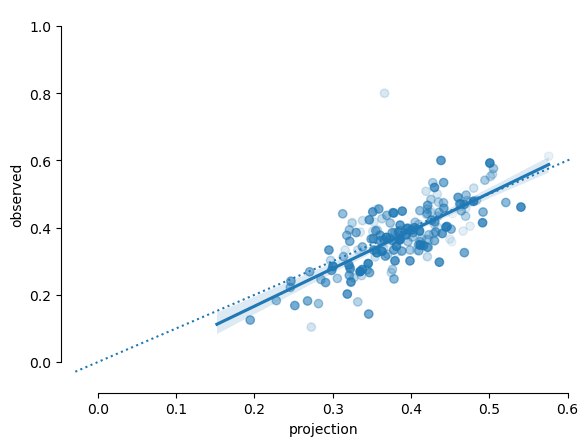
 A scatter plot of projections vs observtions (shaded proportionally to sample size) shows the model to be reasonably well-calibrated.
A scatter plot of projections vs observtions (shaded proportionally to sample size) shows the model to be reasonably well-calibrated.
p_proj = trace.predictions['projected_rate'].mean(dim=('chain', 'draw'))
n = hard_hit_by_season["Events"][2024].fillna(0).to_numpy()
p_obs = hard_hit_by_season["HardHit"][2024].to_numpy() / n
projection = pd.DataFrame(dict(projection=p_proj, observed=p_obs))
ax = sns.regplot(x='projection', y='observed', data=projection, scatter_kws={'alpha':n/n.max()})
sns.despine(ax=ax, offset=10, trim=True);
When Things Go Wrong
With such a simple model that can be applied to virtually any metric, inevitably things will go wrong with certain datasets. The first place to look for symptoms of a problem are in the warnings during model fitting. For example, you may read something like the following:
UserWarning: Chain 0 contains 6 diverging samples after tuning. Increase `target_accept` or reparameterize.
This means that the model is (occasionally) having trouble sampling from the model, which results in a diverging sample. If this happens only a few times things are probably okay, but if there are hundreds or even entirely divergent samples, you will not be able to reliably use inference from the model.
The underlying PyMC model tries to give advice when it can: while you cannot reparameterize this model, it is possible to change the target_accept parameter passed to sample.
pm.sample(target_accept=0.99)
target_accept is the target acceptance rate of the MCMC algorithm, which in PyMC is 0.8 by default. For difficult models, upping this value to 0.9, 0.95 or 0.99 can sometimes solve this issue. Note that higher acceptance rates result in longer runtimes, since it involves taking more steps at every iteration of the model.
If you run into issues with convergence--for example, if the energy plots do not look slimiar--the easiest remedy is to run the MCMC model longer by adding more tuning steps. The default number is 1000, but you can change this with the tune argument.
pm.sample(tune=5000)
Of course, there will be some scenarios where a simple, general model like this will just not work. If there are issues with the data, or the data do not conform to a simple statistical likelihood like a binomial, then you may need to build a bespoke model to account for the particular characteristics of the quantity you are trying to project.
Conclusions
In one sense, the MARCEL model represents the core of almost any viable player projection model: it uses past performance to predict future performance, regresses projections to some population mean, and adjusts for the effects of aging. While I used it here to project hard hit rate via a binomial sampling process, we could just as easily have modeled pitcher fastball velocity with essentially the same model, swapping out the binomial likelhood for a Gaussian. For that matter, it could have been used to project wide receiver sprint speed in football or goalie save percentage in ice hockey.
Re-casting MARCEL in the Bayesian paradigm proved to be a straightforward enhancement that preserved the overall simplicity of the original model. It gave us a natural way of regressing projections to the mean, a principled was of weighting past performance, and a probabilistic measure of uncertainty in our projections. We used the same ingredients for the model, merely implementing them in a different way.
Of course, the Bayesian monkey might not be the best choice for all of your projection needs. Clearly, we've left a lot on the table, and this is by design. It is best to think of MARCEL (Bayesian or otherwise) as a starting point in the development of a performant projection system. With relatively little effort (or additional data), the model could be expanded to account for obvious shortcomings. For example:
- Aging curves for most performance time series are not triangular, as we've assumed here. One might, for example, swap in a quadratic or some other polynomial function, or get fancy and use a spline.
- Further, there is often age-related selection bias at play, whereby older players are not representative of the general population at that age, since only top veterans tend to play into their late thirties and forties. Some type of censoring model can be used to account for this.
- Performance can often be influenced by location. With sufficiently large data sets, its possible to estimate venue effects that can be used to adjust projections to be venue-neutral.
- The weighting scheme implemented by MARCEL is essentially a third-order autoregressive model. It may be worth considering alternative time series models, depending on the metric in question. For example, there may be processes operating at multiple time scales that may influence performance, in which case Gaussian processes can be effective for describing them.
The workflow for constructing sports projection models is really no different than what we recommend for other types of models. Rather than attempting to build a feature-complete model at the outset, start with a baseline model that is easy to understand and implement, then expand according to how that model falls short relative to the goals of the project. The Bayesian MARCEL provides a reasonable starting point for a baseball projection system, not unlike the ordinary least squares model does for regression problems.
This is the sort of thing we do here at PyMC Labs -- squeezing extra value and insights from your data using the power of probabilistic programming! Feel free to get in touch to chat about our approach to sports analytics, if you think we could be helpful 😉 If you want to learn more about hierarchical modeling in particular, this free PyMC tutorial is full of tips and tricks that you may find useful. The "Learn Bayes Stats" podcast also has a huge catalogue of technical episodes, or if you're more of a visual learner, the Intuitive Bayes platform has several high-quality courses.